Overview
The following diagram depicts the application architecture:
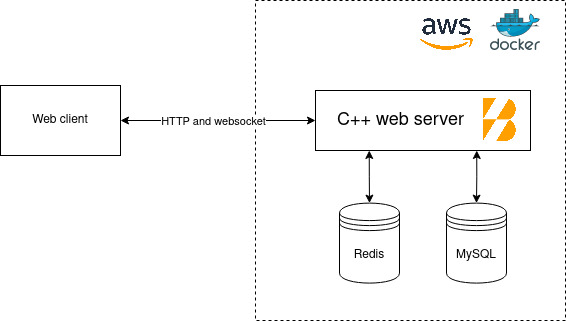
REST API
The REST API is used for operations that do not require low latency, like account creation and authentication. It follows the usual HTTP API conventions, like verbs and status codes. Some error responses (like account creation failures) include additional error information, in JSON format.
Websocket API
Time-sensitive operations, like sending messages, use websockets.
The diagram below depicts how the websocket API works. All events are JSON encoded.

When the client connects, the server sends a hello event, contining all the
data required by the client to build the UI (i.e. available chat rooms
and message history).
When the user types a message, the client sends a clientMessages event. The server
persists it and broadcasts a serverMessages event to all clients, including the
one that originated the message.
On connection, only the latest messages are loaded. The client can request more
by sending a requestMessageHistory event. This implements message pagination
(but see this issue).
See this file for a complete reference on API types.
Server architecture
Async code
All I/O is handled asynchronously, using Boost.Asio. The server uses C++20 coroutines to make async flow easier.
A coroutine is created by calling
boost::asio::co_spawn.
Coroutines are functions with return type boost::asio::awaitable<T>.
Logic that uses coroutines has a similar structure to synchronous code,
which makes reasoning easy.
The server is single-threaded, which makes development much easier. Measurements are still to be performed to determine whether a multi-threaded architecture could pay off (see this issue).
Redis
We use Redis streams to store messages. These are append-only data structures, similar to a commit log. We use one stream per chat room. Each stream element is assigned an ID by Redis. We use this ID as message ID. Note that this makes the message ID unique per chat room.
In the future, we plan to offload old messages to MySQL, to keep Redis structures small (see this issue).
We use Boost.Redis to communicate with Redis asynchronously. Following the recommended Boost.Redis architecture, the server opens a single Redis connection. Boost.Redis takes care of pipelining requests internally to make the most of connection.
The Redis hostname is configured via the environment variable REDIS_HOST.
The Redis instance is never exposed to the internet, so no authentication
or encryption is set up.
MySQL
We use MySQL to store users. Future business objects that are not considered time-critical will also be stored in MySQL.
We use Boost.MySQL to communicate with MySQL asynchronously. Database setup code (i.e. migrations) are currently executed at application startup. A connection is dynamically opened and closed for each request (but see this issue).
The MySQL hostname is configured via the environment variable MYSQL_HOST.
The MySQL instance is never exposed to the internet, so no strong credentials
or encryption are set up (but see
this issue).
Authentication
Clients are authenticated using the /api/login endpoint, using an email and
a password as credentials. Self-registration is possible using the /api/create-account
endpoint. At the moment, no email verification is performed
(see this issue).
Passwords are stored in MySQL, hashed using scrypt.
User sessions are managed using 16-byte session IDs, valid for 7 days and transmitted
using HTTP cookies. Session IDs are stored in Redis and use Redis' key expiry time feature.
Cookies use the HttpOnly and SameSite=Strict attributes to prevent XSS and CSRF
attacks.
Websocket sessions use credentials included in the HTTP upgrade request that initiates the session. If the supplied credentials are invalid, the websocket is closed with a certain code straight after the handshake. Doing this allows the client to detect missing credentials and redirect the user to the login page.
Message broadcasting
Messages are broadcast using an in-memory data structure (the pubsub_service)
that uses Boost.MultiIndex.
This is efficient but contrains the server to a single instance.
It is planned to replace the pubsub_service with a more scalable mechanism,
like Redis channels.
We’ve also considered using Redis XREAD
to subscribe to stream changes. However, XREAD blocks the connection until
an update is received, which doesn’t work well with Boost.Redis single-connection
architecture.
HTTP and websockets
HTTP and websocket traffic is handled using Boost.Beast. The server uses a listener loop, accepting new connections while serving the active ones asynchronously.
Boost.Json and Boost.Describe are used to serialize and parse API data.
Additional considerations
-
The server requires C++17 to build, since that’s the minimum for Boost.Redis to work.
-
The server is built using CMake.
-
We only target Linux servers. The current deployment uses Alpine Linux.
-
The server has unit tests, written using Boost.Test.
-
The server has also integration tests, which exercise the server using the API. These tests use a real database, and are written in Python, using pytest.
Client architecture
The client is web-based and uses Next.js, React and TypeScript. Styles use Tailwind CSS and the MUI library.
Client files are compiled into regular HTML, CSS and JavaScript files, which are then served by the C++ server as static files.
The client has unit tests written in Jest.
Client screens are first designed in Figma before being translated into code. This file contains wireframes for this project.
Building and deploying
For local development, you can build your code using your IDE or invoking CMake directly. See this section for further details. Additionally, code is built, tested and deployed continuously by a GitHub Actions workflow.
Server and client builds are defined in a single Dockerfile, enabling repeatable builds. The CI pipeline uses this Dockerfile to build and test the code. Docker caching has been set up to reduce re-build times.
Both client and server are packaged into a single Docker container. This container is stored in the GitHub container registry.
Redis and MySQL are deployed as separate containers. We use standard Redis and MySQL images, so there is no need to build custom images for DBs.
The server is then deployed to your Linux server of choice via SSH. The script will log into the server, install Docker if not available, and create the relevant Docker objects (in a similar way to what Compose does).
More scalable deployments could make use of Kubernetes or AWS ECS clusters. If that’s something of interest to you, please feel free to open an issue.
|
Note
|
In the current setup, Docker containers in the GitHub container registry have public visibility. If you want to make them private, you will need to set up credentials in your server to authorize your deployment script. |